


Adobe Firefly continua a crescere: nuove funzioni, più velocità, e un controllo creativo sempre più raffinato. Il cuore? La funzione Text to Image, che trasforma descrizioni in immagini con uno stile tutto da guidare.
L’ultima volta che mi sono occupato di Firefly per Italia Grafica risale ad alcuni mesi fa, circa 8 o 9, non molto se li consideriamo in termini assoluti, ma a quel tempo eravamo prossimi al suo secondo compleanno, e la terza release del suo motore generativo stava giusto uscendo dalla fase di beta pubblica.
Se mi passate un parallelismo con i bambini, 8 mesi di crescita nei primi anni di vita non sono propriamente pochi, anzi, e anche il “neonato” Firefly non è rimasto a “gattonare” mentre noi facevamo altro, anzi!
Cos’è successo nel frattempo?
La famiglia dei modelli di intelligenza artificiale si è allargata con il Firefly Video Mode e le manipolazioni audio, e in termini strettamente numerici siamo passati da circa 6 miliardi di immagini generate a oltre 13 (in costante aumento).
Dati che, da soli, non dicono niente dei molti miglioramenti qualitativi occorsi ma che, in un contesto fortemente iterativo come quello dell’arte generativa, possono lasciar ben immaginare il miglioramento esponenziale a cui siamo arrivati semplicemente analizzando continuamente i dati di utilizzo raccolti dagli utenti.
L’interfaccia di lavoro è rimasta sostanzialmente la stessa, al netto di qualche marginale aggiustamento cosmetico e alla comparsa/scomparsa di elementi secondari, pertanto anche il flusso di lavoro possiamo considerarlo ormai consolidato (dell’approccio Adobe in questo senso ne abbiamo già parlato nell’articolo precedente).
Da testo a immagine
Il focus di oggi è il servizio “Da testo a immagine” (o Text to Image, se preferite l’inglese), senza dubbio il cavallo di battaglia del mondo dell’arte generativa basato su intelligenza artificiale.
Come già sicuramente saprete tutti (o quasi), si tratta di una “funzione” che consente di creare immagini a partire da descrizioni testuali, secondo processi basati su reti neurali avanzate addestrate su vasti dataset di immagini e testi, così da apprendere le relazioni tra parole e caratteristiche visive.
Lungi dall’essere l’esempio più complesso di utilizzo dell’AI, è tuttavia quello attualmente più diffuso e conosciuto, proprio perché le modalità di interazione (e relativi risultati) sono spesso alla portata anche di un’utenza non esperta.
Il cuore di tutto il processo generativo è il Prompt, la cui formulazione diventa cruciale per l’ottenimento di risultati in linea con il pensiero dell’utente, e in questo FireFly è forte di un multilinguismo che conta più di 100 linguaggi.
Riguardo la buona formulazione del prompt il web è prodigo di risorse di tutti i tipi, e in sintesi possiamo schematizzarne i punti principali come segue:
Descrizione → Specificare il soggetto, l’azione, l’ambientazione e lo stile.
Esempio: “Cubetto di ghiaccio, fondo scuro”
Stili e tecniche → Indicare riferimenti artistici, tecniche o stili specifici.
Esempio: “Illuminazione da studio, iperrealistico”
Parametri visivi → Aspetti tecnici come prospettiva, colore, composizione.
Esempio: “Ripresa grandangolare, elevato dettaglio, soggetto centrale”
Negazioni → Serve generalmente nei modelli avanzati per evitare dettagli indesiderati.
Esempio: “No acqua, no neve, nessun elemento sullo sfondo”.
Più la descrizione è dettagliata e più aumentiamo la probabilità di ottenere quello che desideriamo, ma dato che la sindrome da foglio bianco (o blocco dello scrittore) è molto diffusa, Firefly propone un’ampia serie di esempi visivi di Composizione e Stile per accompagnare la sperimentazione dell’utente nell’apprendimento e affinamento del prompt.
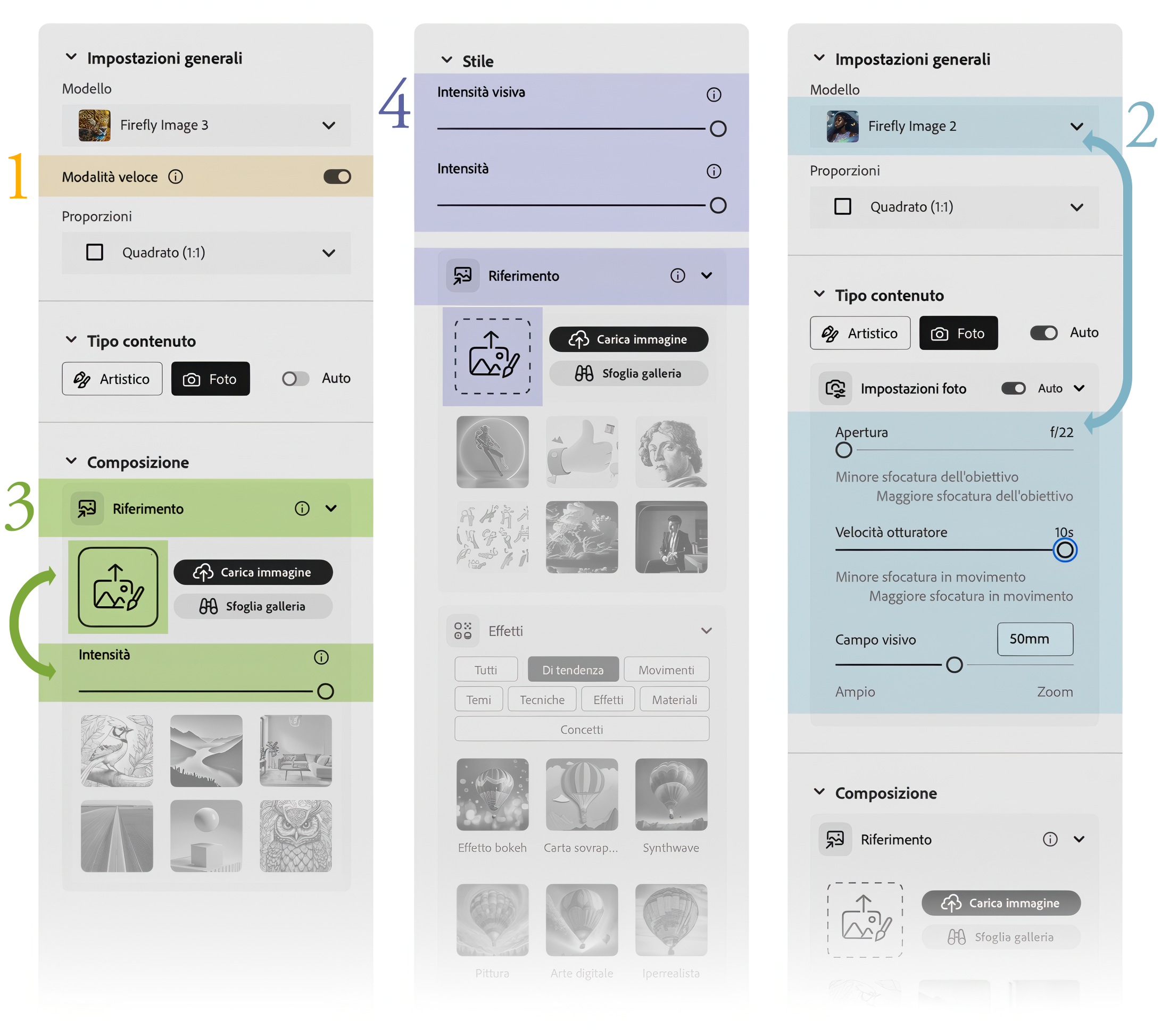
1. La Modalità veloce
Da alcuni mesi Adobe ha introdotto questa modalità, attiva di default e presente solo nella versione 3 del modello generativo, che intende ridurre i tempi di calcolo (quindi di attesa) nei processi.
Per molti aspetti può essere considerata come una negoziazione win-win: le immagini generate sono da 512×512 pixel anziché 2048×2048, alleggeriscono quindi il carico di lavoro e i tempi di attesa di un fattore teorico di 16, ergo Adobe consuma meno e voi aspettate meno per vedere le prove. Costo: 1 credito.
Se vi piace una delle soluzioni potete ingrandirla o, per meglio dire, generarla alla risoluzione massima di 4 Mpixel e introducendo quindi più dettagli, al costo di un ulteriore credito, (l’ingrandimento riguarda tutto il set di 4 immagini a cui appartiene l’immagine scelta).
Alcuni danno più peso al fatto che, creando immagini già grandi, si spenderebbe solo 1 credito, ma il risparmio di tempo è, dal mio punto di vista, più importante che rischiare di esaurire i crediti del mio abbonamento, soprattutto quando studio i processi iterativi dei miei prompt.
2. Il modello V2
Ma come? È già operativa in pianta stabile la versione 3 e ancora parliamo della 2? Risposta breve: si.
Risposta meno breve: è l’unica che presenta impostazioni relative all’inquadratura, come se si stesse lavorando con una fotocamera “tradizionale”.
Impostazioni come l’apertura, la velocità dell’otturatore e la lunghezza focale (qui Campo visivo) non sono disponibili nei parametri della versione 3, quindi se avete queste esigenze di controllo dovrete necessariamente fare un passo indietro e gestirle da qui.
Niente impedisce comunque di determinare così l’inquadratura che più ci piace e poi indicare il risultato come riferimento di Composizione, di cui parleremo al punto seguente.

3. La Composizione
La composizione è probabilmente il punto più cruciale per la realizzazione dei nostri progetti, grazie a questa sezione infatti possiamo indicare quale struttura visiva dovrebbe rispettare il processo generativo, in combinazione con quanto descritto dal prompt. La Galleria offre di base alcune immagini che potremmo definire “di prova”, ma il divertimento inizia quando si iniziano a caricare le nostre immagini, anche (e soprattutto) creandole ad hoc per i nostri scopi.
Nel nostro caso (Figura 2) ho preparato diverse riferimenti di composizione:
– Il logo n.1 è piatto, ma FF è ugualmente in grado di restituirgli aspetti tridimensionali in relazione al prompt inserito e/o allo Stile da noi indicato;
– Il logo n.2 ha una tridimensionalità ben definita da un passaggio in Illustrator, in questo modo FF rispetterà più fedelmente i volumi, anche se il cliché del 3d a prospettiva centrale non è raro ottenerlo anche con il logo n.1;
– il logo n.3 ha una estrusione molto più particolare (anche qui grazie a Illustrator), che non potrete in alcun modo ottenere in FF se non caricando questa immagine nella Composizione. In altre parole: con il logo 1 potreste ottenere risultati analoghi a quelli del logo 2, ma in nessun caso saranno sovrapponibili a quelli del logo 3.
Il cursore dell’Intensità è fondamentale per condizionare l’impatti del riferimento sul risultato finale: spostandolo a sinistra verrà dato più credito al prompt a discapito dell’immagine di riferimento, spostandolo a destra invece verrà rispettata molto di più l’immagine di riferimento a discapito di quanto scritto nel prompt.
Le posizioni sono “soltanto” tre, ma già così c’è da perdersi tra tutte le possibili interazione che vengono generate tra queste e le prossime impostazioni.
4. Lo Stile
Se la Composizione poteva essere al primo posto per criticità compositiva, lo Stile lo segue di certo a breve distanza, anche se questo podio sommario potrebbe presentare innumerevoli eccezioni che ne ribalterebbero l’ordine di arrivo.
Se non viene selezionato niente né viene caricata alcuna immagine, questa sezione presenta un solo cursore, quello dell’intensità visiva.
Ciò che regola questo cursore è descritto in modo molto generico dalla “i” che trovate nell’interfaccia utente, e anche nelle varie guide più o meno ufficiali viene spesso “spiegato” con delle vere e proprie supercazzole.
Proverò a dare una sintesi basata su quanto ho capito mettendo insieme quelle super… con le mie esperienze e qualche altro spunto ragionato trovato in rete durante le notti insonni: spostandolo a sinistra (sono 9 livelli) avremo risultati più basici ed essenziali, spostandolo a destra invece aumenteremo la complessità e, di conseguenza, i particolari e i dettagli.
Possiamo applicare questi comportamenti sia se il contenuto è impostato su artistico che su foto, con le opportune differenze di stile.
Trovare delle definizioni accurate e per me soddisfacenti su quanto sopra non sembra tuttavia possibile, per lo meno al momento, questo perché le interazioni con il prompt e le altre impostazioni introducono variabilità non indifferenti e, aspetto non secondario, l’arte generativa restituisce sempre risultati diversi, che sarebbero recuperabili in maniera univoca solo se fossimo in possesso del cosiddetto Seed (cioè il numero che ne codifica la generazione), e con FF questo non è attualmente esplicitato.
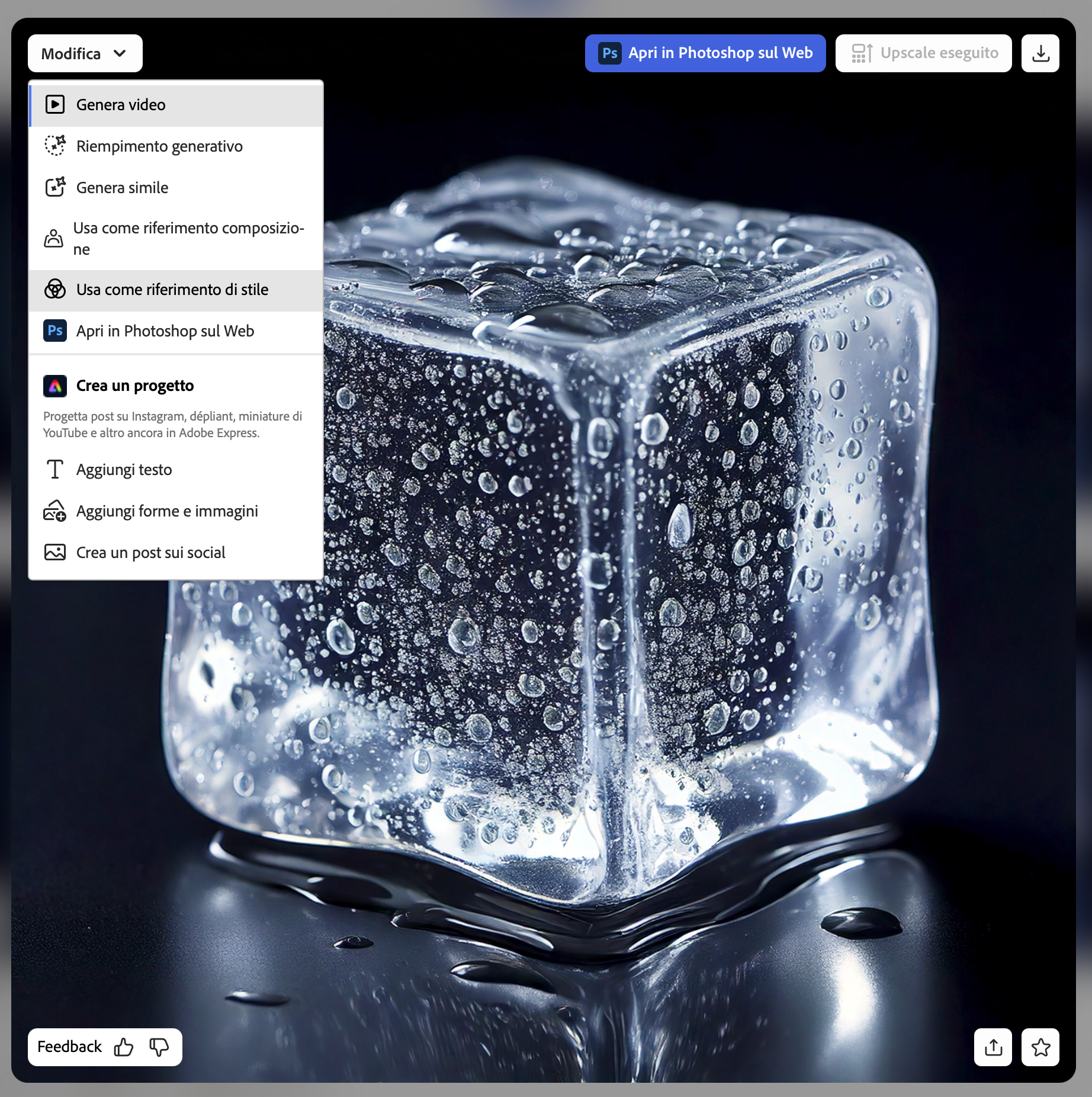
Possiamo parzialmente aggirare questa “mancanza” (è una scelta ben precisa di Adobe) usando due comandi a cui si accede tramite il pulsante di condivisione (in basso a destra nell’immagine, a fianco della stellina dei preferiti, che da qualche tempo non funziona): Copia collegamento all’immagine e Salva in libreria, in questo modo saremo sicuri di ripartire sempre da una stessa base.



{kind=link}